Antes de que comencemos, démonos unos minutos para ver hasta donde hemos llegado:
Arrays

Ventajas
- Nos permiten guardar información de un mismo tipo de dato
- La guardan de manera contigua (osea junta, una al lado de la otra) en memoria.
- Gracias a lo anterior podemos acceder a cualquier posición que queramos mediante un simple paso, en un tiempo constante sin importar si el el primero o el décimo elemento.
Desventajas
- No es dinámico, es decir debemos especificar su tamaño cuando lo declaramos
- Por lo tanto, es muy muy difícil y tardado añadir o quitar elementos (es más ni siquiera es seguro que haya mas espacio libre contiguo en memoria para añadir más elementos)
Listas Enlazadas

Ventajas
- Son super fáciles de hacer crecer pues sus elementos NO son contiguos en memoria.
Desventajas
- Ya NO toma lo mismo acceder a un elemento cualquiera, pues tendremos que recorrer TODA la lista comparando uno por uno. Es más podemos decir que el tiempo de búsqueda en el peor caso es O(n)
…
Entonces:
¿Qué pasa si quiero algo que sea mucho más rápido para localizar elementos y que al mismo tiempo sea mucho más fácil de hacerlo crecer si es necesario?
Pues justo para eso se inventaron las:
Tablas Hash
«Heredero de las listas enlazadas e hijo de la reina array»
Usando una definición de libro: Las Tablas Hash son estructuras de datos que se utilizan para almacenar un número elevado de datos sobre los que se necesitan operaciones de búsqueda e inserción muy eficientes.
En palabras simples una Tabla Hash es solo la unión de un array y un función que llamamos Función Hash.

Partes de una Lista Hash
Podemos entonces decir que una Tabla Hash se forma por 3 elementos:
-
Una tabla de un tamaño razonable para almacenar los pares (clave, valor).
-
Una función “hash” que recibe la clave y devuelve un índice para acceder a una posición de la tabla.
-
Un procedimiento para tratar los casos en los que la función anterior devuelve el mismo índice para dos claves distintas. Esta situación se conoce con el nombre de colisión.
…¿Qué demonios? ¿Cómo lo hace?
Una Tabla Hash almacena un conjunto de pares “(clave, valor)”.
- Dato/Clave/Key: Es el parámetro de entrada, es el «dato que queremos guardar»
- Valor/Indice/HashValue/Code: Es un número, un entero positivo si nos ponemos exquisitos que nos indica donde debemos guardar nuestro «dato» o «clave» dentro de la tabla.

Es decir, es casi como hacer que nuestra información nos diga donde debería ir, en vez e ordenarla nosotros mismos.
El único problema que existe con esta estructura es que es HORRIBLE para ordenar información, son simplemente horribles.
Así que: USALA CUANDO NO TE IMPORTE SI LA INFORMACIÓN SE GUARDA DE MANERA ORDENADA.
Función Hash
Esto es la clave, la Función Hash es la clave de toda la magia, porque nos indica donde hay que guardar nuestro dato y también donde es que debemos buscarlo si es que queremos alguna vez.
Esta función SIEMPRE regresa lo mismo: Un entero positivo. Usaremos ese número que nos regresa para saber en que índice de un array vamos a guardar la información
Debido a esto es muy importante que esta se comporte de manera consistente.
¿Qué necesito para que mi Función Hash sea asombrosa?

Pero mira esa función papu
Hay muchas cosas, pero nos vamos a enfocar en varios puntos claves, es decir tu función debe ser:
- Tiene que minimizar las posibilidades de que ocurra una colisión como de lugar.
- Usará TODA la información que sea proporcionada para maxilar la cantidad de códigos hash.
- Es determinista, es decir, si le das una entrada x, siempre, siempre tendrá que regresarte el mismo número como resultado.
- Distribuya los valores de manera equitativa (osea que cosas como «gatos» y «gata» acaben en lugares muy muy diferentes de la tabla).
- Repite, tiene que ser capaz de generar indices muy diferentes para datos muy parecidos.
- Usa una función «sencilla» no hagas 50,000 operaciones para generar cada indice o todo el tiempo de ejecución te la pasarás haciendo eso.
Ahora, dicho esto, hay muchísimas muchísimas buenas función en internet y deberías usar eso a tu favor, escribir una de estas funciones es más un arte.

El Tamaño de la Tabla
El tamaño de una tabla hash es el otro parámetro que debe ser ajustado con cierto cuidado.
Por ejemplo, si el tamaño es demasiado pequeño, digamos 1, de nuevo la tabla se comporta como una lista encadenada.
En cambio, si el tamaño es enorme, el malgasto de memoria es evidente, puesto que habrá un elevado número de posiciones cuya lista de colisiones está vacía.
Colisiones
Antes de hablar de operaciones veamos un último problema con las Tablas Hash, las colisiones, como te has dado cuenta insertar es una operación bastante simple, pero hay un grave problema.. ¿Qué pasa si la clave Hash me da el mismo resultado para dos datos diferentes que quiero guardar?
Por ejemplo si queremos ordenar palabras basados en su primera letra:



…
Pues hay dos formas de lidear con esto:
Team Linear Probing
Esta solución le vale un comino la vida y si respuesta es simple: Si esta ocupado ese lugar simplemente busca el más próximo que este libre.

La solución #1
Y esta forma de pensar lleva un problema, y es que empieza a pasar que si mandar ahora tu dato a ese lugar «disponible cerca» ..¿Qué pasará cuando queramos meter el valor que si que debería estar en ese lugar que acabamos de ocupar?
La Respuesta: Otra colisión. Este problema se conoce como «clustering» y esta es principalmente la razón por la cual no usamos este método. Solo trae más problemas.
Y lo peor es que hace que ahora para buscar elementos volvamos a un caso de O(n), es decir todo nuestro trabajo NO valió para nada. :`(
Pero no se preocupen, hay otra solución…
Team Separate Chaining
Esta solución propone lo que veíamos al principio…¿Recuerdas las listas enlazadas?…¿Cuál era su mayor ventaja?
Este team propone que el array donde guardemos la información no sea mas que un array de punteros hacia listas enlazadas…¡Y esa es una solución cojonuda!
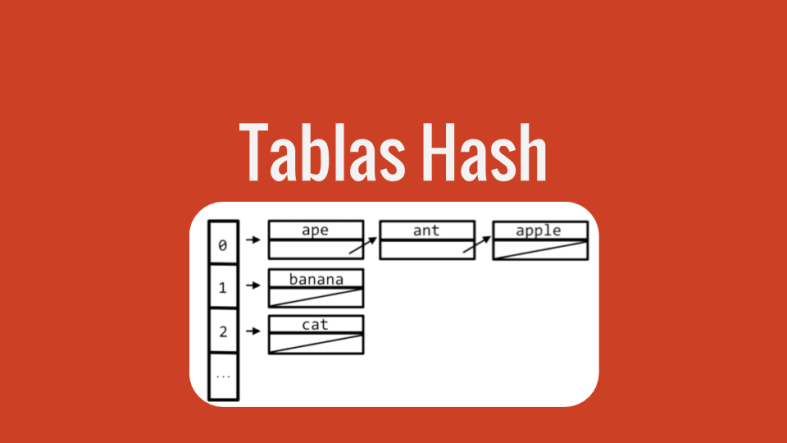
Soluciona todos nuestros problemas y hace que nuestra estructura se vea más o menos así:

¿Ven? ¡Parece una Tabla! Por eso la llaman Tabla Hash
Fíjate que diferentes posiciones de la tabla pueden tener listas de diferente longitud, o incluso vacías.
Dada una clave, el proceso de búsqueda consiste en calcular primero su índice mediante la función de hash, y a continuación buscar esa clave en la lista de colisiones.

Ejemplo de una Hash Table usando Listas
Con esto se logra que el nuevo peor caso posible sea O(n/k)…Y si, a nivel de «complejidad» es lo mismo, pero en el mundo real esa k si que vale, pues si k= 100 por ejemplo hará que programa se ejecute 100 veces más rápido. ¡A eso yo llamo eficiencia!
 |
 |
 |
|














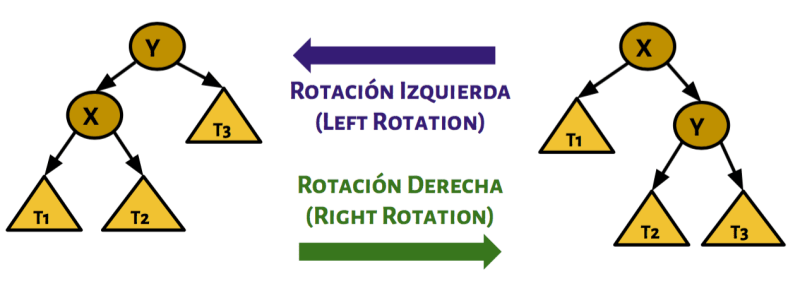
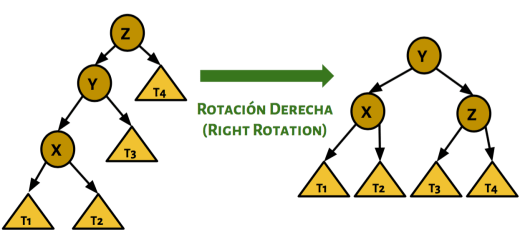








 Los arboles son casi casi crear un grafo en una computadora, así que antes que nada tengo algo que decirte:
Los arboles son casi casi crear un grafo en una computadora, así que antes que nada tengo algo que decirte: Estas son esencialmente diferentes a las listas y todas sus parientes. Esta estructura no es lineal (Osea que puede haber nodos que apunten a más de un elemento).
Estas son esencialmente diferentes a las listas y todas sus parientes. Esta estructura no es lineal (Osea que puede haber nodos que apunten a más de un elemento).



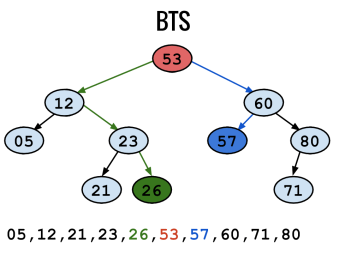
 Los árboles binarios son mis favoritos, son muy my poderosos, pero ¿Porque me deberían de interesar?
Los árboles binarios son mis favoritos, son muy my poderosos, pero ¿Porque me deberían de interesar?






















 Las pilas, son todo un clásico porque no son la forma mas tradicional de agrupar datos, pero una vez que las comprendes veras que son muy muy útiles.
Las pilas, son todo un clásico porque no son la forma mas tradicional de agrupar datos, pero una vez que las comprendes veras que son muy muy útiles.












